With Computex, there’s been a ton of news about Ice Lake (hereafter ICL) and the Sunny Cove core (SNC). Wikichip, Extremetech and Anandtech among many others have coverage (and there will be a lot more), so I won’t rehash this.
I also don’t want to embark on a long discussion about 14nm vs 10nm, Intel’s problems with clock speeds, etc. Much of this is covered elsewhere both well and badly. I’d rather focus on something I find interesting: a summary of what SNC is bringing us as programmers, assuming we’re programmers who like using SIMD (I’vedabbledabit).
I’m also going to take it as a given that Cannonlake (CNL) didn’t really happen (for all practical purposes). A few NUCs got into the hands of smart people who did some helpful measurements of VBMI, but from the perspective of the mass market, the transition is really going to be from AVX2 to “what SNC can do”.
While I’m strewing provisos around, I will also admit that I’m not very interested in deep learning, floating point or crypto (not that there’s anything wrong with that; there are just plenty of other people willing to analyze how many FMAs or crypto ops/second new processors have).
Also interesting: SNC is a wider machine with some new ports and new capabilities on existing ports. I don’t know enough about this to comment, and what I do remember from my time at Intel isn’t public, so I’m only going to talk about things that are on the public record. In any case, I can’t predict the implications of this sort of change without getting to play with a machine.
So, leaving all that aside, here are the interesting bits:
ICL will add AVX-512 capability to a consumer chip for the first time. Before ICL, you can’t buy a consumer-grade computer that runs AVX-512 – there are various Xeon D chips that you could buy to get AVX-512 or you could buy the obscure CNL NUC or laptop (maybe), but there wasn’t a mainstream development platform for this.
So we’re going straight from AVX2, which is an incremental SSE update that didn’t really extend SSE across to 256 bits in a general way (looking at VPSHUFB and VPALIGNR makes it starkly clear that, from the perspective of a bit/byte-basher, AVX2 is 2x128b) – all the way to AVX-512.
AVX-512 capability isn’t just a extension of AVX 2 across more bits. The way that nearly all operations can be controlled by ‘mask’ registers allows us to do all sorts of cool things that previously would have required mental gymnastics to do in SIMD. The short version of the story is that AVX-512 introduces 8 mask registers that allow most operations to be conditionally controlled by whether the corresponding bit in the mask register in on or off (including the ability to suppress loads and stores that might otherwise introduce faults).
Further, the AVX-512 capabilities in ICL are a big update on what’s there in Skylake Server (SKX), the mainstream server platform that would be the main way that most people would have encountered AVX-512. When you get SNC, you’re getting not just SKX-type AVX-512, you’re getting a host of interesting add-ons. There include, but are not limited to (I told you I don’t care about floating point, neural nets or crypto):
This one is the only extension that we’ve seen before – it’s in Cannonlake. VBMI adds the capability of dynamically (not just a fixed pattern shuffle) shuffling bytes as well as words, “doublewords” (Intel-ese for 32-bits), and “quadwords” (64 bits). All the other granularities of shuffle up to a 512-bit size are there in AVX-512 but bytes don’t make it until AVX512_VBMI.
Not only that, the shuffles can have 2-register forms, so you can pull in values over a 2x512b pair of registers. So in addition to VPERMB we add VPERMT2B and VPERMI2B (the 2-register source shuffles have 2 variants depending on what thing gets overwritten by the shuffle result).
This is significant both for the ‘traditional’ sense of shuffles (suppose you have a bunch of bytes you want to rearrange before processing) but also for table lookup. If you treat the shuffle instructions as ‘table lookups’, the byte operations in VBMI allow you to look up 64 different bytes at once out of a 64-byte table, or 64 different bytes at once out of a 128-byte table in the 2-register form.
The throughput and latency costs on CNL shuffles are pretty good, too, so I expect these operations to be fairly cheap on SNC (I don’t know yet).
VBMI also adds VPMULTISHIFTQB – this one works on 64-bit lanes and allows unaligned selection of any 8-bit field from the corresponding 64-bit lane. A pretty handy one for people pulling things out of packed columnar databases, where someone might have packed annoying sized values (say 5 or 6 bits) into a dense representation.
VBMI2
VBMI2 extends the VPCOMPRESS/VPEXPAND instructions to byte and word granularity. This allow a mask register to be used to extract (or deposit) only the appropriate data elements either out of (or into) another SIMD register or memory.
VPCOMPRESSB pretty much ‘dynamites the trout stream’ for the transformation of bits to indexes, ruining all the cleverness (?) I perpetrated here with AVX512 and BMI2 (not the vector kind, the PDEP/PEXT kind).
VBMI2 also adds a new collection of instructions: VPSHLD, VPSHLDV, VPSHRD, VPSHRDV. These instructions allow left/right logical double shifts, either by a fixed about or a variable amount (thus the 4 variants) across 2 SIMD registers at once. So, for either 16, 32 or 64-bit granularity, we can effectively concatenate a pair of corresponding elements, shift them (variably or not, left or right) and extract the result. This is a handy building block and would have been nice to have while building Hyperscan – we spend a lot of time working around the fact that it’s hard to move bits around a SIMD register (one of these double-shifts, plus a coarse-grained shuffle, would allow bit-shuffles across SIMD registers).
VPOPCNTDQ/BITALG
I’m grouping these together, as VPOPCNTDQ is older (from the MIC product line) but the BITALG capabilities that arrive together with VPOPCNTDQ for everyone barring the Knights* nerds nicely round out the capabilities.
VPOPCNT does what it says on the tin: a bitwise population count for everything from bytes and words (BITALG) up to doublewords and quadwords (VPOPCNTDQ). We like counting bits. Yay.
VPSHUFBITQMB, also introduced with BITALG, is a lot like VPMULTISHIFTQB, except that it extracts 8 single bits from each 64-bit lane and deposits it in a mask register.
GFNI
OK, I said I didn’t care about crypto. I don’t! However, even a lowly bit-basher can get something out of these ones. If I’ve mangled the details, or am missing some obvious better ways of presenting this, let me know – be aware that the below picture is an accurate presentation of what I look like when dealing with these instructions:
GF2P8AFFINEINVQB I’ll pass over in silence; I think it’s for the real crypto folks, not a monkey with a stick like me.
GF2P8AFFINEQB on the other hand is likely awesome. It takes each 8 bit value and ‘matrix multiplies’ it, in a carryless multiply sense, with a 8×8 bit matrix held in the same 64-bit lane as the 8 bit value came from.
This can do some nice stuff. Notably, it can permute bits within each byte, or, speaking more generally, replace each bit with an arbitrary XOR of any bit from the source byte. So if you wanted to replace (b0, b1, .. b7) with (b7^b6, b6^b5, … b0^b0) you could. Trivially, of course, this also gets you 8-bit shift and rotate (not operations that exist on Intel SIMD otherwise). This use of the instruction effectively assumes the 64-bit value is ‘fixed’ and our 8-bit values are coming from an unknown input.
One could also view GF2P8AFFINEQB as something where the 8-bit values are ‘fixed’ and the 64-bit values are unknown – this would allow the user to, say, extract bits 0,8,16… from a 64-bit value and put it in byte 0, as well as 1,9,17,… and put it in byte 1, etc. – thus doing a 8×8 bit matrix transpose of our 64-bit values.
I don’t have too much useful stuff for GF2P8MULB outside crypto, but it is worth noting that there aren’t that many cheap byte->byte transformations that can be done over 8 bits that aren’t straightforward arithmetic or logic (add, and, or, etc) – notably no lanewise multiplies. So this might come in handy, in a kind of monkey-with-a-stick fashion.
So the addition of a vectorized version of this instruction – VPCLMULQDQ – that allows us to not just use SIMD registers to hold the results of a 64b x 64b->128b multiply, but to carry out up to 4 of them at once, could be straightfowardly handy.
Longer term, carryless multiply works as a good substitute for some uses of PEXT. While it would be nice to have a vectorized PEXT/PDEP (make it happen, Intel!), it is possible to get a poor-man’s version of PEXT via AND + PCLMULQDQ – we can’t get a clean bitwise extract, but, we can get a 1:1 pattern of extracted bits by carefully choosing our carryless multiply multiplier. This is probably worth a separate blog post.
I have a few nice string matching algorithms that rest on PEXT and take advantage of PEXT as a useful ‘hash function’ (not really a hash function, of course). The advantage in the string matching world of using PEXT and not a hash function is the ability to ‘hash’ simultaneously over ‘a’, ‘abc’ and ‘xyz’, while ensuring that the effectively ‘wild-carded’ nature of ‘a’ in a hash big enough to cover ‘abc’ and ‘xyz’ doesn’t ruin the hash table completely.
Conclusion
So, what’s so great about all this? From an integer-focused programmer’s perspective, ICL/SNC adds a huge collection of instructions that allow us – in many cases for the first time – to move bits and bytes around within SIMD registers in complex and useful ways. This radically expands the number of operations that can be done in SIMD – without branching and potentially without having to go out to memory for table accesses.
It’s my contention that this kind of SIMD programming is hugely important. There are plenty of ways to do ‘bulk data processing’ – on SIMD, on GPGPU, etc. This approach is the traditional “well, I had to multiply a huge vector by a huge matrix” type problem. Setup costs, latencies – all this stuff is less important if we can amortize over thousands of elements.
On the other hand, doing scrappy little bits of SIMD within otherwise scalar code can yield all sorts of speedups and new capabilities. The overhead of mixing in some SIMD tricks that do things that are extremely expensive in general purpose registers is very low on Intel. It’s time to get exploring (or will be, in July).
Conclusion Caveats
Plenty of things could go wrong, and this whole project is a long-term thing. Obviously we are a long way away from having SNC across the whole product range at Intel, much less across a significant proportion of the installed base. Some of the above instructions might be too expensive for the uses I’d like to put them (see also: SSE4.2, which was never been a good idea). The processors might clock down too much with AVX-512, although this seems to be less and less of a problem.
If you have some corrections, or interesting ideas about these instructions, hit me up in the comments! If you just want to complain about Intel (or, for that matter, anyone or anything else), I can suggest some alternative venues.
There is a persistent meme out there that matching regular expressions with back-references is NP-Hard. There is a post about this and the claim is repeated by Russ Cox so this is now part of received wisdom.
None of these claims are false; they just don’t apply to regular expression matching in the sense that most people would imagine (any more than, say, someone would claim, “colloquially” that summing a list of N integers is O(N^2) since it’s quite possible that each integer might be N bits long). It depends on the generally unfamiliar notion that the regular expression being matched might be arbitrarily varied to add more back-references.
These constructions rely on being able to add more things to the regular expression as the size of the problem that’s being reduced to ‘regex matching with back-references’ gets bigger.
Suppose, instead, as per more common practice, we are considering the difficulty of matching a fixed regular expressions with one or more back-references against an input of size N.
Is this task is in P? That is, is there a polynomial-time algorithm in the size of the input that will tell us whether this back-reference containing regular expression matched?
Note that back-references in a regular expression don’t “lock” – so the pattern /((\wx)\2)z/ will match “axaxbxbxz” (EDIT: sorry, I originally fat-fingered this example). So, sadly, we can’t just enumerate all starts and ending positions of every back-reference (say there are k backreferences) for a bad but polynomial-time algorithm (this would be O(N^2k) runs of our algorithm without back-references, so if we had a O(N) algorithm we could solve it in O(N^(2k+1)). Unfortunately, this construction doesn’t work – the capturing parentheses to which the back-references occur update, and so there can be numerous instances of them.
Note that even a lousy algorithm for establishing that this is possible suffices. So if there’s a construction that shows that we can match regular expressions with k backreferences in O(N^(100k^2+10000)) we’d still be in P, even if the algorithm is rubbish. I’ve read that (I forget the source) that, informally, a lousy poly-time algorithm can often be improved, but an exponential-time algorithm is intractable. So knowing that this problem was in P would be helpful.
So I’m curious – are there any either (a) results showing that fixed regex matching with back-references is also NP-hard, or (b) results, possibly the construction of a dreadfully naive algorithm, showing that it can be polynomial?
In the last post, I talked about some first impressions of programming SIMD for the ARM architecture. Since then, I’ve gotten simdjson working on our ARM box – a 3.3Ghz eMag from Ampere Computing.
I will post some very preliminary performance results for that shortly, but I imagine that will turn into a giant festival of misinterpretation (take your pick: “Intel’s lead in server space is doomed, says ex-Intel Principal Engineer” or “ARM NEON is DOA and will never work”) and fanboy opinions, so I’m going to stick to implementation details for now.
I had two major complaints in my last post. One was that SIMD on ARM is still stuck at 128-bit. As of now, there does not seem to be a clever way to work around this…
The other complaint, a little more tractable, was the absence of the old Intel SIMD standby, the PMOVMSKB instruction. This SSE instruction takes the high bit from every byte and packs it into the low 16 bits of a general purpose register. There is also an AVX2 version of it, called VPMOVMSKB, that sets 32 bits in similar fashion.
Naturally, given the popularity of this instruction, AVX512 does something different and does all this – and much more – via ‘mask’ registers instead, but that’s a topic for another post.
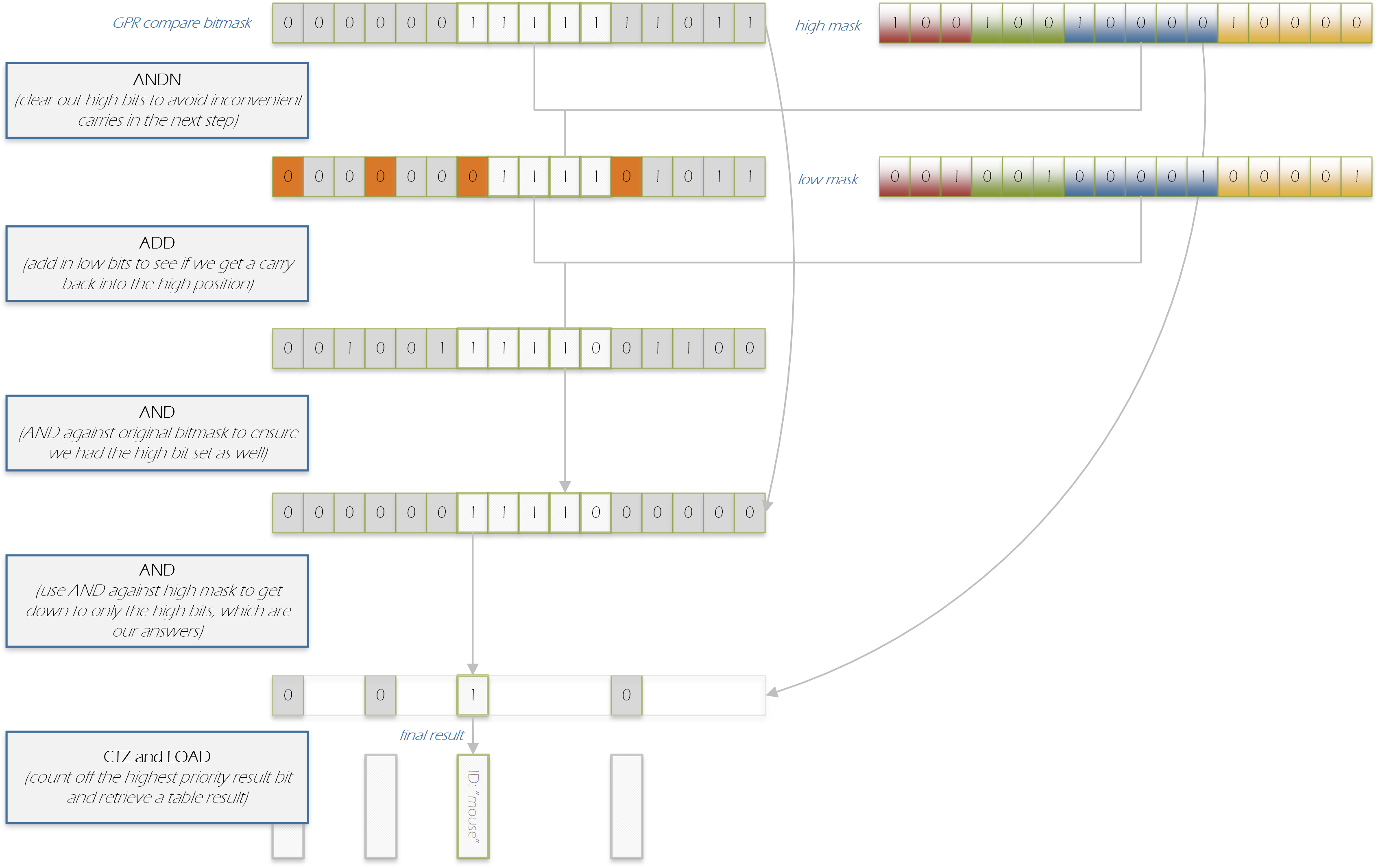
At any rate, we want this operation a fair bit in simdjson (and more generally). We often have the results of a compare operation sitting in a SIMD register and would like to reduce it down to a concise form.
In fact, what we want for simdjson is not PMOVMSKB – we want 4 PMOVMSKB’s in a row and want the results to be put in a single 64-bit register. This is actually good news – the code to do this on ARM is much cheaper (amortized) if you have 4 of these to do and 1 destination register.
So, here’s how to do it. For the purposes of this discussion assume we have already filled each lane of each input vector with 0xff or 0x00. Strictly speaking the below sequences aren’t exactly analogous to PMOVMSKB as they don’t just pick out the high bit.
The Simple Variant
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This requires 4 logical operations (to mask off the unwanted bits), 4 paired-add instructions (it is 3 steps to go from 512->256->128->64 bits, but the first stage requires two separate 256->128 bit operations, so 4 total), and an extraction operation (to get the final result into our general purpose register).
Here’s the basic flow using ‘a’ for the result bit for our first lane of the vector, ‘b’ for the second, etc. We start with (all vectors written left to right from least significant bit to most significant bit, with “/” to delimit bytes):
a a a a a a a a / b b b b b b b b / c c c c c c c c / ...
Masking gets us:
(512 bits across 4 regs)
a 0 0 0 0 0 0 0 / 0 b 0 0 0 0 0 0 / 0 0 c 0 0 0 0 0 / ...
Those 3 stages of paired-add operations (the 4 vpaddq_u8 intrinsics) yield:
(256 bits across 2 regs)
a b 0 0 0 0 0 0 / 0 0 c d 0 0 0 0 / 0 0 0 0 e f 0 0 / ...
(128 bits across 1 reg)
a b c d 0 0 0 0 / 0 0 0 0 e f g h / i j k l 0 0 0 0 / ...
(64 bits across 1 reg; top half is a repeated 'dummy' copy)
a b c d e f g h / i j k l m n o p / q r s t u v w x / ...
… and then all we need to do is extract the first 64-bit lane. Note that doing this operation over a single 128-bit value to extract a 16-bit mask would not be anything like 1/4 as cheap as this – we would still require 3 vpaddq operations (we could use the slightly cheaper 64-bit forms for the second and third versions).
It is possible to combine the results in fewer instructions with a mask and a 16-bit ADDV instruction (which adds results horizontally inside a SIMD register). This instruction, however, seem quite expensive, and I cannot think of a way to extract the predicate results in their original order without extra instructions.
The Interleaved Variant
However, there’s a faster, and intriguing way to do this, that isn’t really analogous to anything you can do on the Intel SIMD side of the fence.
Let’s step back a moment. In simdjson, we want to calculate a bunch of different predicates on single-byte values – at different stages, we want to know if they are backslashes, or quotes, or illegal values inside a string (under 0x20), or whether they are in various character classes. All these things can be calculated byte by byte. So it doesn’t really matter what order we operate on our bytes, just as long as we can get our 64-bit mask back out cheaply in the original order.
So we can use an oddity (from an Intel programmer’s perspective) of ARM – the N-way load instructions. In this case, we use LD4 to load 4 vector registers – so 512 bits – in a single hit. Instead of loading these registers consecutively, the 0th, 4th, 8th, … bytes are packed into register 0, the 1st, 5th, 9th, … bytes are packed into register 1, etc.
In simdjson, we can operate on these bytes normally as before. It doesn’t matter what order they are in when we’re doing compares or looking up shuffle tables to test membership of character classes. However, at the end of it all, we need to reverse the effect of the way that LD4 has interleaved our results.
Here’s the ‘interleaved’ version:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
We start with compare results, with result bits designated as a, b, c, etc (where a is a 1-bit if the first byte-wise vector result was true, else a 0-bit).
4 registers, interleaved
a a a a a a a a / e e e e e e e e / i i i i i i i i / ...
b b b b b b b b / f f f f f f f f / j j j j j j j j / ...
c c c c c c c c / g g g g g g g g / k k k k k k k k / ...
d d d d d d d d / h h h h h h h h / l l l l l l l l / ...
We can start the process of deinterleaving and reducing by AND’ing our compare results for the first register by the repeated bit pattern { 0x01, 0x10 }, the second register by {0x02, 0x20}, the third by { 0x04, 0x40} and the fourth by { 0x08, 0x80 }. Nominally, this would look like this:
In practice, while we have to AND off the very first register, the second and subsequent registers can be combined and masked with the first register using one of ARM’s “bit select” operations, which allows us to combine and mask the registers in one operation (so the above picture never really exists in the registers). So with 4 operations (1 AND and 3 bit selects) we now have our desired 64 bits lined up in a single accumulator register, in a slightly awkward fashion.
If our result bits are designated as abcdef… etc., our accumulator register now holds (reading from LSB to MSB):
a b c d 0 0 0 0 / 0 0 0 0 e f g h / i j k l 0 0 0 0 ...
We can then use the paired-add routine to combine and narrow these bytes, yielding a 64-bit result.
So we need 4 logical operations, 1 paired add, and an extract. This is strictly cheaper than our original sequence. The LD4 operation (it is, after all, and instruction that allows us to load 512 bits in a single instruction) is also cheaper than 4 128-bit vector loads.
The use of this transformation allows us to go from spending 4.23 cycles per byte in simdjson’s “stage1” to 3.86 cycles per byte, an almost 10% improvement. I haven’t quantified how much benefit we get from using LD4 versus how much benefit we get from this cheaper PMOVMSKB sequence.
Conclusion
There is a substitute for PMOVMSKB, especially at larger scale (it would still be painfully slow if you only needed a single 16-bit PMOVMSKB in comparison to the Intel operation). It’s a little faster to use the “interleaved” variant, if interleaving the bytes can be tolerated.
On a machine with 128-bit operations, requiring just 6 operations to do the equivalent of 4 PMOVMSKBs isn’t all that bad – notably, if this was a SSE-based Intel machine, the 4 PMOVMSKB operations would need to be followed by 3 shift and 3 OR operations to be glued together into one register. Realistically, though, Intel has had 256-bit integer operations since Haswell (2013) so the comparison should really be against 2 VPMOVMSKB ops followed by 1 shift+or combination) – or, if you really want to be mean to ARM, a single operation to the AVX-512 mask registers followed by a move to the GPRs.
Still, it’s better than I thought it would be…
I think I thought up these tricks, but given that I’ve been coding on ARM for a matter of days, I’m sure there’s plenty of people doing this or similar. Please leave alternate implementations or pointers to earlier versions of my implementation in the comments; I’m happy to give credit where it is due.
Side note: though it is a latent possibility in simdjson, the “interleaved” variant actually allows us to combine our results for adjacent values more cheaply than we would be able to if we had our input in non-interleaved fashion.
If we were evaluating a pair of predicates that are adjacent in our data, and wanted to do this combination in the SIMD side (as opposed to moving the results to the GPR side and calculating things there – in Hyperscan, we had occasion to do things both ways, depending on specifics), we can combine our results for bytes 0, 4, 8, 12 … with our results for bytes 1, 5, 9, 13 … with a simple AND operation. It is only for the combination of bytes 3, 7, 11, 15 with the subsequent bytes 4, 8, 12, 16 that we need to do a comparatively expensive vector shift operation (EXT in ARM terms, or PALIGNR or PSLLDQ for Intel folks).
In a way, the cheapness of the ‘vertical’ combinations in this PMOVMSKB substitute hints at this capability: adjacent bytes are easier to combine, except across 32-bit boundaries (not an issue for the code in this post).
This would be a key consideration if porting a Hyperscan matcher such as “Teddy” to ARM. I might build up a demo of this for subsequent posts.
(the pictured dish is apparently materials for “Buddha Jumps Over The Wall”, named for its ability to seduce away vegetarians – sadly it uses shark fin so has some ethical issues…)
I’ve done a lot of SIMD coding. However, aside from dabbling with a bit of 32-bit ARM coding during the early Hyperscan era (back before the Intel acquisition of Sensory Networks), it’s been nearly all Intel SIMD – SSE2 through to AVX512.
Recently I’ve been working on an ARM port of simdjson, our fast (Gigabytes/second) SIMD parser. I’ll be uploading preliminary ARM SIMD code for this soon. While the experience is fresh in my mind, I thought I’d write up some first impressions of ARM AArch64 SIMD programming (good, bad and just plain ugly).
The Good
First of all, orthogonality. it’s really nice to program with a SIMD instruction set where one (usually) doesn’t have to wonder whether there will be a an operation for a given data size. Every time I went looking for an operation on bytes, I found it (this is by contrast to Intel SIMD programming, where a whole raft of operations don’t exist for bytes and some don’t exist for 16-bit “word” quantities either).
Orthogonality of these operations is a huge relief to the programmer – it’s less work to commit things to memory, and fewer “what the hell” moments later when you realize something that should exist doesn’t. For example, when doing the “bits to indexes” work my original paper notes on the code happily had an operation that didn’t exist (masked 512-bit OR using a byte-granularity kreg).
Second, multiple-table permutes: TBL and TBX can take multiple registers – up to 4 – as inputs. Thus, you can permute over up to 512 bits. This is a leap-frogging race here – with VBMI and Cannonlake, Intel will allow 2 AVX512-bit registers to be used in a VPERMI2B or VPERMT2B. More on latencies later (I would like to praise these ARM SIMD operations more but, despite many happy claims about how fast these ops are in some architectures – e.g. A12 – I can’t find any documentation).
Note for Intel people – TBL/TBX yield “zero” or “no operation” on out of range indexes, which is a contrast to PSHUFB (with its odd behavior governed by the high bit) or VPERM*, where only the low-order bits affect what the permute does. This seems to be a neutral change; sometimes the PSHUFB behavior is annoying, sometimes it’s useful.
Third, horizontal operations and pairwise operations. This is something that exists spottily on Intel SIMD, but ARM allows a wide variety of operations to be either applied across the whole vector or be done as a pairwise approach. ADD and MAX/MIN are pretty handy in both contexts.
Fourth, multiple vector interleaved load and store. This is pretty awesome, and the latency/throughput numbers aren’t too bad for at least A75.
Some elements of ARM SIMD coding are pleasant but no longer a significant advantage. The comprehensive range of compare operations is now matched by AVX512. Overall, it’s still a very pleasant instruction set to work with.
The Bad
There is no equivalent of PMOVMSKB on ARM. People have been complaining about this for years. I have a couple not-too-terrible workarounds for this – especially if one has lots of these operations to do at once (e.g. 4×128 bulk PMOVMSKB equivalent to a 64-bit register) which will be the topic of a blog post in the near future. There is at least a decent version involving masking and a series of paired-add operations. So this can be worked around.
It’s 2019 and we’re still doing 128-bit SIMD. I’m excited to see Scalable Vector Extensions (SVE), but… it was announced late 2016 and the only place you can use this extension is a Fujitsu supercomputer? The absence of SVE from the Neoverse announcement was worrying; this will be a processor shipping almost 4 years after SVE was announced that seemed like a logical fit for SVE. ARM really needs to announce a roadmap for SVE. Is anyone going to support it?
The Ugly
Documentation. OK, so we have tons of different ARM variants out there supporting AArch64. Why do none of them – aside from ARM itself – publish tables of instruction latency and throughput? Plenty of people complain about Intel’s documentation, but the Software Optimization Guide coupled to all the supplementary information (Agner Fog, uops.info) is a wonderful source of information by comparison.
ARM apparently has made real strides in openness – I can get a lot of information off their site without registering or being force-signed-up for marketing material (there are still some regrettable exceptions to this – there’s a Neon programmers guide that forces you to sign up for marketing emails, then turns out to be old…). However, most of the other vendors (Apple, Marvell, Ampere) seem to provide zero information to the public (there might be a super-secret NDA version?). This is depressing: you guys do understand that it helps you to have people write good code for your architecture, right?
Also, holes in the tables of throughput and latency are never welcome, no matter which vendor you are. I’d like to wax more enthusiastic about TBL and TBX but even ARM’s data on this has holes (no throughput data).
Conclusion
All up it’s been fairly pleasant to port simdjson to ARM. Missing operations are counter-balanced by a lot of nice new tricks. I’d say the biggest source of pain at this stage is how scarce information on non-ARM implementations of the instruction set.
If anyone has better software optimization resources for ARM (or if there’s a secretive ARM equivalent of Agner Fog or uops.info lurking out there), please comment or send me an email.
Well, if that doesn’t put off some readers, I don’t know what will…
A technique that we recently disclosed for our JSON parser (see the paper or recent blog post) is something I think I invented (please set me straight if this is known since the glory days of HAKMEM, or whatever).
We want to find all the space between quotes – so if we have an input like:
abc xxx "foobar" zzz "a"
We can easily have a bitvector:
000000001000000100000101
… corresponding to the quote positions (reading left-to-right from input bytes to bits here).
However, we really want to know that the strings “foobar” and “a” are inside the quotes and nothing else is. What we really want is this:
00000000.111111.00000.1.
… where the 1 bits appear over the things that are inside our quotes – I use ‘.’ to indicate that we don’t really care what the results are for the quote characters themselves (the technique that I detail later will set the opening quote to 1 in this mask and the closing quote to 0).
So how do we find this property?
One solution is to calculate the parallel prefix over XOR of our bits. So given bits b0, b1, b2, b3 our result is b0, b0^b1, b0^b1^b2, b0^b1^b2^b3, and so on. This means that if you get a ‘parity’ result – for a bit, it’s on if there are an odd-numbered count of bits that are on to its left (LSB side) otherwise it’s off.
A nice way to calculate this is to do a carryless multiply by an all-ones (or 2-complement -1 value). This is provided in Intel’s PCLMULQDQ instruction (part of the CLMUL extension, which is pretty specific!) . This instruction is a weird one – it takes two 64-bit values (selected out of a pair of 128-bit registers by using immediates to select which 64-bit value to get within each register) and produces a 128-bit result. The low-order bits are what we need here (oddly, the high-order bits after multiplying by -1 in this case work out as the parallel prefix over XOR from the opposite direction, a property that I haven’t thought of a good use for).
Here’s the code:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
In the above code, “odd ends” comes from a previous stage and represents quotes that need to be ‘escaped’ as they were preceded by an unescaped backslash, and “cmp_mask_against_input” is just the standard SIMD comparison against a character that we do to find a ‘”” character (the usual PCMPEQB->PMOVMSKB dance).
The only real weirdness in this code, above, is that we need to factor in our previous quoting status from the previous iteration. So if we ended inside a quote, the “prev_iter_inside_quote” value is all 1s – this allows us to invert the sense of our quote mask.
This exotic instruction (PCLMULQDQ) is pretty slow in terms of latency – on a modern Skylake processor it’s still latency 6. So, in simdjson, we needed to rearrange our code a bit to hide that latency and find some other work to do. But it’s still quite fast overall as long as you don’t follow it with anything that depends on its result (the reciprocal throughput of this instruction is 1 on Skylake).
If you read the Intel® Architecture Instruction Set Extensions and Future Features Programming Reference (pdf) (and who doesn’t?), you’ll note that this instruction is going to get extended on Icelake – it will be turned into a true SIMD instruction (with 4 carryless multiplies over a 512-bit register) rather than one that performs one operation and really just uses SIMD for operand size.
It’s a little tidbit, but I liked it. If you’re working over a pretty large chunk of data, with a lot of little strings in it, your alternative is to process one quote pair at a time, which will be quote slow by comparison. And, as per the name of the blog, the technique is branch free.
Let me know in the comments if you’ve found any other fun uses for carry-less multiply or have any war stories.
I’m pleased to report that Hyperscan, the regular expression matcher that ate my life from 2008 through 2018, finally has a paper (pdf) – it’s being presented this week at NSDI ’19.
Anyone who lacks a taste for my discursive bullshit could just stop reading this blog post there, and just go read the paper…. Bye!
It’s a good paper and it works as a standalone read. I’d like to call out a few things in it as particularly interesting and worth reviewing. I’d also like to call out a few things in Hyperscan that we couldn’t write about for reasons of space – we were hard up against the space limits for any conceivable conference paper, so there were whole subsystems and implementation strategies that we couldn’t write about. I will also mention a few aspects of Hyperscan historically that didn’t make it into the Hyperscan 4.x release series (the first open source release of Hyperscan and a substantial API change) nor the Hyperscan 5.x release series (a major release number that largely celebrates the now Australian-free aspect of Hyperscan).
Hyperscan Summary
It’s a software based, large-scale regex matcher designed to match multiple patterns at once (up to tens of thousands of patterns at once) and to ‘stream‘ (that is, match patterns across many different ‘stream writes’ without holding on to all the data you’ve ever seen). To my knowledge this makes it unique.
RE2 is software based but doesn’t scale to large numbers of patterns; nor does it stream (although it could). It occupies a fundamentally different niche to Hyperscan; we compared the performance of RE2::Set (the RE2 multiple pattern interface) to Hyperscan a while back.
Most back-tracking matchers (such as libpcre) are one pattern at a time and are inherently incapable of streaming, due to their requirement to backtrack into arbitrary amounts of old input.
Hyperscan was the product of a ‘pivot’ for a startup called Sensory Networks that was founded in 2003 to do regex on FPGA. I joined in 2006 and spent some time doing regex on GPGPU, before we decided that implementing regular expressions on GPCPU was a better idea. We worked in a much diminished company from 2009 (5 staff members!) until our acquisition by Intel in October 2013.
Future Thingies
Hyperscan and RE2 continue in their niches. There are a number of other projects out there – even a few hardware regular expression matchers struggle on – but I’ll have to get to other projects in another post.
It’s possible that something much simpler than Hyperscan could get a considerable portion of the benefit of Hyperscan, while being a more tractable code base for adaptation, porting to other CPU architectures or exotic architectures (GPGPU, for example), alternate use cases like bioinformatics, etc. I have some ideas in this area under the dubious code name “Ultimate Regex Engine the Third” (ure3) – Hyperscan itself was, originally “Ultimate Engine the Second”. If anyone is interested, get in contact.
Pattern Matching Techniques Roundup
Hyperscan Things That Made It Into The Paper
Pattern Decomposition (Section 3)
A key idea of Hyperscan is that if we have a complex regular expression – say:
42:/<\s*object[^>]*data\s*\x3A[^,>]*base64/smi
We can observe that there are a lot of parts of this pattern that are simply literal strings: “object”, “data”, “base64”. It’s a lot easier and cheaper to match literals rather than do a full regular expression implementation, so breaking up this pattern (an easy one, as it is simply ‘one thing after another’) into several components allows us to remove the strings from the finite automata matching task.
A rudimentary version of this is ‘pre-filtering’ – we could just make sure we saw all 3 strings, then run the pattern (although this is tricky in streaming mode – more details at some other time). But this still means we’re matching all the characters in those three strings in an automata. Given that our methods for matching NFAs are quite sensitive to the number of states, it’s better to have smaller automata.
String Matching: “FDR” (Section 4.1)
FDR is one of a long list of string matching engines that I’ve built. It’s been fairly effective, although it gets a bit cranky at large string counts. See the paper for details, as there’s only so many times I can explain what a “bucketed SIMD shift-or matcher with supercharacters” is.
The FDR matcher is used for moderate-to-large string match cases – typically between around 80 and tens of thousands of strings – and uses SIMD not for scanning many characters at once, but holding a much larger set of simple state machines than could be done with a general purpose register.
This is worth noting given the debates about vector machines – not every use of SIMD is oriented towards applying simple operations over great long vectors of data. FDR is a bucketed shift-or matcher that works better at 128 bits (8 buckets, 16 wide) than it would at 64 bits – there’s no obviously urgent extension to 256, 512 or for that matter, 2048 bits.
Freud said, sometimes a cigar is just a cigar; similarly, sometimes a SIMD register is just a SIMD register.
The Glushkov construction is a way of getting an ε-free NFA (“epsilon free”); that is, an NFA that does not make transitions from state to state without processing a character. This makes it considerably easier to build state machines with simple bit vector operations (although the successor function, showing which states can follow other states, is not necessarily trivial).
The LimEx matcher is an evolution of several earlier matchers. The “Limited NFA” could only allow states to jump to 0,1 or 2 states ahead (generalized to a larger number, eventually, but still not allowing irregular transformations). The “General NFA” used multiple partitions to allow arbitrary jumps after the Method of Four Russians. The appallingly stupidly-named “LimGen” NFA combined the two, gathering only states requiring a ‘non-limited’ transition using a PSHUFB instruction (yes, that one again, fans), and doing a table lookup.
All of these exotic techniques fell away to the simple strategy: do ‘limited’ transitions (a certain number of fixed-distance jumps only) then work through all the remaining states and do “Exceptions” (the “Ex” in “LimEx”). This covers quite a bit of plumbing for accept states, triggering and reading of bounded repeats, etc. It’s not pretty, but it works.
Hyperscan Things That Didn’t Make It Into The Paper
The following sections are not an exhaustive list; there are many more optimizations and transformations that don’t make it in. A few are below:
Graph transformations: redundancy, unreachable components, etc. – we built an abstract NFA graph (also a Glushkov NFA, but tailored towards representing our workload, not a direct implementation) and apply transformations. We can detect redundant work in an NFA and eliminate it, expand out literal paths, etc.
Bounded Repeat Analysis and implementation: handling of single-character bounded repeats: e.g. /foo[^\n]{1024}bar/ is quite challenging. We ‘discover’ such repeats in our NFA graph, and have specialized code to implement this class of repeats.
Other string matchers: we have a small-group literal matcher called “Teddy” (that uses SIMD; to this day, the best explication of Teddy is in the Rust reimplementation of it, even if they could benefit from using the rest of my compiler algorithm; my logic to merge multiple strings into a bucket is at least mildly sophisticated).
DFA implementation: Alex Coyte, one of our engineers (now at Google) always said “DFAs are awesome”. They are; they are faster and simpler than NFAs. We used them quite a bit (when we could, and when they made sense). We had a pretty straightforward implementation of DFAs without too many exotic components, but there are some tricks to making DFAs smaller.
NFA and DFA acceleration: when it’s possible to check that an automata, whether NFA or DFA, can’t leave its local neighborhood of current states without seeing easily detected ‘event’, it’s possible to use SIMD to scan for that event.
For example, the pattern fragment /[^\n]*foo/ can scan for a newline, which breaks out of the \n state, or an ‘f’, which may commence the start of a ‘foo’.
This extends even to NFAs, where we can take the closure of all possibly active ‘accelerable’ states and scan ahead for events.
Specialized engines, like “Sheng“, and many others. The ‘Castle’ engine, for example, efficiently handles many bounded repeats at once, improving overall performance but also radically reducing the amount of state we have to store.
Lookaround assertions: we use a similar technique to my SMH matching engine to, upon receipt of a literal match, to augment the power of the literal match by verifying that the characters around the match will match at the regex level. So if we extracted the string ‘foobar’ from a regex (to use a modified version of our earlier example)’/<\s*object[^>]*\s\dfoobar\d[^,>]*base64/’
we can implement the character class lookarounds to check that we’ve seen ‘\s\dfoobar\d’ before running a full-fledged NFA matcher for the other parts of the pattern.
… and many others
Hyperscan Things That Didn’t Make It Into Open Source Hyperscan
Ports to non-x86 platforms. Hyperscan had ports to MIPS, ARM, PowerPC and Tilera at one stage. These ports were a lot of hassle to maintain, and I don’t think it takes a genius to see how these ports were not particularly strategic for Intel to devote resources to.
Capturing subexpressions: at once stage we had an experimental product that (in block mode only, not streaming) could accurately model libpcre’s capturing semantics. This worked by scanning the data backwards with a backwards version of the pattern, making a trace of the states visited, and tracing forwards through the backward state trace in order to correctly model the behavior that libpcre would have done. This was possible since when we’re tracing forwards through the backwards trace and following 1-bits in our states, we know they will lead to an accept state.Even more fun was implementing a version of this that checkpointed our backwards state traces periodically, allowing us to store O(sqrt(N)) states in our state trace, at the expense of having to scan twice as much (a generalization would have been to allow us to store O(k*pow(N, 1/k)) states with a cost of scanning k times as much.
This had the feel of one of those tricky algorithm interview questions… overall, capturing support it was fun to work on, but no-one wanted it commercially. We probably wouldn’t do it this way today.
Acknowledgements
We have already mentioned the pioneering work of Victor Glushkov. His work was introduced to us at Sensory Networks by the excellent textbook Flexible Pattern Matching in Strings by Gonzalo Navarro and Mathieu Raffinot. Professor Navarro has also written many excellent papers over the years, so if you can’t afford the book, do check out his publications page. His output is by no means confined to regular expressions, but his treatment of NFA implementations is very good.
A great deal of hard work went into Hyperscan over the years. Version 1.0 was the initiative of Peter Duthie, whose startup Ground Labs is going strong. Alex Coyte, Matt Barr and Justin Viiret worked all the way through from the early days at Sensory Networks through to the end of the Sydney-based Intel DCG Lab. I’d also like to thank Xiang Wang, Yang Hong, Harry Chang, Jiayu Hu and Heqing Zhu from Intel; KyoungSoo Park from KAIST for their work on the paper, as well as the Hyperscan team in general, past and present.
Daniel Lemire and I have spent some time this year working on a fast JSON parser. You can read about it in paper form at arXiv here and the repo is here.
In this blog post, I’ll provide an informal summary of the paper and some background as to the thinking behind the system.
What it is
simdjson is a parser from JSON input to an immutable tree form (a “DOM” in XML terminology). It’s not a full-featured library; it doesn’t allow you to modify the JSON document and write it back out.
simdjson is a fully featured parser – it doesn’t just scan through bits of the JSON looking for particular fields. That’s an extension which we have thought about but we don’t really have good benchmarks for that.
simdjson validates its input. Being generous about accepting malformed input is a rabbit hole – how do you define the semantics of handling a malformed document?
Here’s our performance, against the closest C/C++ competitors we measured, on a range on inputs on a Intel Skylake processor (a i7-6700 running at 3.4 GHz in 64 bit mode) – for full performance details, read the paper!
It’s pretty fast – we seem to be 2-3x faster than the next most reasonable alternative (the primary sources of variability are string and number handling – different JSON documents have different amounts of this kind of work to do). We’re probably competitive with Mison (one of our major inspirations) but we don’t have source code so we can’t tell – and we’re doing a lot more work than Mison. Specifically, Mison isn’t validating and doesn’t build a parse tree.
We provide everything required to repeat our experiments, so if you want to verify our results or test them under different assumptions or against different workloads or parsers, it should be very easy to do that.
Why it is fast
The chief point of difference between simdjson and systems such as RapidJSON and sajson lies in the “Stage 1” of simdjson; the part of the system that detects the locations of structural and pseudo-structural characters from the input. This system operates with large scale and regular operations over 64 bytes of the input at once, and can take advantage of both SIMD operations (when examining characters and character classes) as well as 64-bit bitwise operations (when applying transformations on the masks obtained from the SIMD operations). As such, it can achieve “economies of scale” as compared to a step-by-step approach.
For example, an input that consists of a section comprising two key/value pairs:
“result_type”: “recent”,
“iso_language_code”: “ja”
… enters and leaves the condition of ‘being in a string’ 4 times in under 64 characters. A loop which involves step-by-step scanning of our input would typically not benefit from SIMD due to the relatively short stings, and will need to perform relatively slow operations to detect the next string delimiter. By contrast, our stage 1 code would detect all string begin and end markers with a fixed-cost set of operations (albeit an admittedly complex set). Further, our code can do this without data-dependent conditional branches, which will bring our pipeline to a crashing halt on the the first mispredict.
How it works
Just like the old Soviet-era joke about ‘mat’ (the amazing sub-dialect of Russian swearing) usage by workers in the missile factory, we have two stages, and one goes into the other.
There used to be four stages, and this may show up in a few places in old issues and comments.
Stage 1 uses SIMD to attempt to discover the significant parts of the document that need to be fed into the parser, which is Stage 2. The job of Stage 1 is not necessarily to validate what happens. Instead, the job of Stage 1 is to expose what Stage 2 needs to see – so we need to find the set of structural characters such as [, ], {, }, comma, colon, etc. but we also need to find potential starting characters for atoms such as “true”, “false”, “null” and the numbers. Further, we need to find the starts of errors – so if whitespace or one of these other structural characters is followed by some erroneous string, we need to expose that string to stage 2 to reveal an error.
These subsidiary not-quite-structural characters we refer to as “pseudo-structural characters”: things falling after whitespace or other structural characters, that are not safely tucked inside strings. There’s a fair bit of bit-bashing to find them, but it is all quite mechanical.
To get all the way through stage 1 is a fairly mechanical straight-line process. It is almost entirely branch-free, with a couple exceptions (UTF-8 checking and handling of large numbers of structural characters at the end of stage 1). Stage 1 proceeds as follows:
Validation of UTF-8 across the whole input.
Detection of odd-length sequences of backslashes (that will result in escaping the subsequent character)
Detection of which characters are “inside” quotes, by filtering out escaped quote characters from the previous step, then doing a parallel prefix sum over XOR (using the PCLMULQDQ instruction with an argument of -1 as the multiplier) to turn our escaped quote mask into a mask showing which bits are between a pair of quotes.
Detection of structural characters and whitespace via table-based lookup (implemented with a pair of VPSHUFB instructions).
Detection of pseudo-structural characters (those characters I talked about in the summary of stage 1 that need to be exposed to the subsequent stage 2 for error detection and atom handling).
Conversion of the bitmask containing structural and pseudo-structural characters into a series of indexes.
Stage 2 is considerably less clean and branch free. It operates as a goto-based automata with a stack and validates that the sequence of structural and pseudo-structural characters that have passed in correspond to valid JSON. It also handles atom, number and string validation and, as it goes, constructs our ‘tape’ representation (a navigable, if immutable, tree of JSON elements).
If there’s enough interest, I may do a detailed code walk-through. It’s my belief that many of the steps are fairly novel or novel; to my knowledge, I invented the use of PCLMULQDQ to balance quote pairs for this work and the PSHUFB-based table lookup was also my invention while I worked on the Hyperscan project (which continues, at Intel, unburdened of its awkward load of Australians). However, it would not surprise me to find that many of the techniques are independently invented somewhere else: we found that we had independently invented the techniques used in the remarkable icgrep and the technique that I was so proud of in “Sheng” had been invented by Microsoft before. So maybe one day I’ll invent something of my own for real…
Why it exists – what’s the idea here?
We were curious about how far parsing can be done with SIMD instructions. Stage 1 represents the current limit for us – Stage 2 is only sporadically SIMD and is extremely branchy. So we got as far as we could.
It’s worth stepping back and talking about the original 4-stage design. Initially the bits->indexes transformation occupied a separate stage, but why were there stages 3 and 4? Initially, stage 3 was branch free. It operated over the indexes, but through a series of supposedly clever conditional moves and awkward design, it was able to process and validate almost everything about the input without ever taking a branch (for example, it used a DFA to validate most of the local correctness of the sequence of structural and pseudo-structural characters). It also built a very awkward predecessor of our ‘tape’ structure, with just enough information to traverse our tapes. It then deferred all awkward ‘branchy’ work to a stage 4 (handling of validation of individual atoms, ensuring that {} and [] pairs matched, number and string validation, and cleanup of the awkwardness of the tape structure allowing a more conventional traversal of the tapes).
Fun fact: stage 3 was originally called the “ape_machine” (being a combination of a state_machine and a tape_machine), while stage 4 was the “shovel_machine”, which followed the ape_machine and cleaned up its messes.
Those who have worked with me before may recognize the penchant for cutesey code-names; simdjson doesn’t really have any, now that the ape and shovel machines are put out to pasture. We couldn’t even think of a particularly good name (sadly “Euphemus”, helmsman for Jason and the Argonauts, has already been taken by another project with a similar general task area, and none of the other Argonauts have names that are nearly as amusing).
While stage 3 wasn’t SIMD, it was branch-free and thus avoided the awkwardness of branchy, conditional-heavy processing. Thus, in theory, on a modern architecture, it could run very fast, overlapping the handling of one index with the handling of the next index. The problem is that it pushes a bunch of awkward, branchy work into stage 4.
The sad truth is: sooner or later, you have to take the conditional branches. So pushing them into a late stage didn’t solve the problem. If there is a certain amount of awkward conditional work do to, eventually one must do it – this is the software equivalent of the psychoanalytic “return of the repressed“.
Thus, our new “stage 2” is the pragmatic alternative. If we’re going to take unpredictable branches, we may as well do all the work there.
I’m still on the hunt for more parallel and/or branch-free ways of handling the work done in stage 2. Some aspects of what we are doing could be done in parallel (computation of depth and/or final tape location could likely be done with parallel prefix sum) or at least fast (we could go back to a fast automata to handle much of the global validation or the local validation of things like numbers and strings). But the current system is pretty fast, so the parallel system would have to work really well to be competitive.
It’s still worth thinking about this for more modern or upcoming architectures (AVX 512, ARM’s SVE) or unusual architectures (the massive parallelism of GPGPU). This would be a good research project (see below).
What next? (and/or “I’m interested, how can I help?”)
There are a few interesting projects in different directions. Similar tricks to what we’ve done could be used for other formats (notably CSV parsing, which should be doable with something analogous to our stage 1). We could also try to extend these techniques more generally – it’s our hope that a more systematic version of our SIMD tricks could be picked up and incorporated into a more general parser.
There’s quite a bit of software engineering still to do with the JSON parser if someone wants to use it as a generally usable library. It’s a few steps beyond the typical caricature of an academic project (“it worked once on my graduate student’s laptop”) but it isn’t really battle-hardened.
The structure of simdjson is not particularly oriented towards reuse. A helpful set of transformations would be to break it into smaller, reusable components without compromising performance. Particularly egregious is the use of many hard-coded tables for the VPSHUFB-based character matcher; not only does this hard code the particular characters and character classes, it cannot be reused in a situation as-is in a number of situations (e.g. overly numerous character classes or ones where a desired character class includes one with the high bit set).
The aforementioned work with retargeting this work to AVX512, ARM NEON, ARM SVE or GPGPU (CUDA or OpenCL) would be interesting as an exercise. These are varying degrees of difficulty.
Note that there are some opportunities to engage in SIMD on a more massive scale – we could use SIMD not just for character class detection but for many of the intermediate steps. So we would process, on AVX512, 512 characters at once, then do our various manipulations on 512-bit vectors instead of 64-bit words. There are some nice possibilities here (including a fun sequence to calculate XOR-based parallel prefix over 512 bits rather than 64; a nice challenge that I have worked out on paper but not in practice). We also have examined bits->indexes for AVX512 as well. However, this may fall into the category of the drunk man “looking for their keys under the lamppost not because he dropped them there, but because the light is better”. It is Stage 2 that needs to be made parallel and/or regular, not Stage 1!
An ambitious person could attack Stage 2 and make it considerably more parallel. I confess to having failed here, but a patient soul may benefit from my copious notes and half-baked ideas. If you are serious, get in touch.
Acknowledgements
Daniel Lemire provided most of the initial impetus towards this project, put up with a ludicrous churn of ideas and half-formed implementations from me, handled many of the tasks that I was too fidgety to do properly (number handling, UTF-8 validation) and did nearly all the real software engineering present in this project. Without his ceaseless work, this code would be a few half-formed ideas floating around in a notebook.
The original Mison paper (authors: Yinan Li, Nikos R. Katsipoulakis, Badrish Chandramouli, Jonathan Goldstein, Donald Kossmann) provided inspiration for the overall structure and data-flow of the earlier parts of ‘stage 1’ – our implementations are different but the early steps of our Stage 1 follow Mison very closely in structure.
The vectorized UTF-8 validation was motivated by a blog post by O. Goffart. K. Willets helped design the current vectorized UTF-8 validation. In particular, he provided the algorithm and code to check that sequences of two, three and four non-ASCII bytes match the leading byte. The authors are grateful to W. Mula for sharing related number-parsing code online.
Post-script: Frequently Unanswered Questions
How much faster could this run if the JSON was in some weird format e.g. “one record per line”?
Why do people use so much JSON, anyhow? Why don’t they use a more efficient format?
Why not write this in <insert favorite language X here>? Wouldn’t a rewrite in X be just inherently better/faster/safer?
Something a little different today. For my regular readers, I promise to try to keep the number of “opinion/rant” posts to a minimum and we’ll be back on our regular technical content in a few days. It’s pretty easy to just whack the keys and issue Epic Pronouncements on things, but the effect is limited:
In any case, I have had this post kicking around in my brain in some form for years.
Preliminary Comments, Background, Disclaimers
I’m going to talk about “algorithms startups”: this is a vague term to mean a startup that is oriented around building and selling (in some form) an algorithm – as opposed to building a complete solution and trying to make money directly from customers. I don’t mean a “pure” IP play where you invent something, patent the hell out of it, and try to extract money from world+dog. I’m assuming we’re talking about inventing something that didn’t exist before, writing the code yourselves, and trying to make money more or less directly from the code.
My experience (short version): I joined a startup (Sensory Networks, founded in 2003) while it was quite large in 2006, watched it lose traction until the end of 2008, and formed part of a small team (5 people, at the start of 2009) which took a small chunk of additional funding and took the business to a decent exit (I claim ‘decent’, in terms of the scale and funding of the startup since 2009) in 2013.
We built a software-based regular expression matcher called Hyperscan which we sold as a closed-source commercial library. Hyperscan was later (2015) open-sourced at Intel. I don’t know how to make money directly off open source so if you’re hoping for insights there I don’t have any experience.
Sensory Networks wasn’t planned to be an pure ‘algorithms startup’ – we just wound up there by default; focusing on the core of the task was the only viable way forward from 2009 onward.
I should note that many – most, even – of the interesting things that happened at Sensory Networks and subsequently at Intel are commercial-in-confidence. So, boringly, I am not going to be reeling forth exciting details of evaluations and commercial deals made with brand name companies That You’ve Probably Heard Of. There will be no exciting insider revelations, just affirmation of principles you’ve probably heard 50 times before for the most part. I will also not discuss acquisition mechanics.
I draw my experience both from Sensory Networks and my continued experiences with the Hyperscan product but also from watching closely a lot of other startups in the area. While we did some things right, we got a lot of stuff wrong, too. Unfortunately, a bunch of the things we didn’t do right are tied up with things that I can’t talk about or they are speculative (it’s easy to speculate about things you should have done but hard to tell whether pursuing alternate strategies would have worked better).
I’m assuming that most readers have already heard about the idea of continuous integration, fixing bugs first, etc. so we can take that stuff as read.
Many of the principles here were applied by much better software engineers than I am; I may talk a great line about testability and API design and fuzzing and so on, but most of the real work in this area was done by the core Sensory Networks team of developers from the restart in 2009 through to the Intel acquisition and beyond: Matt Barr, Alex Coyte, and Justin Viiret.
It’s also clear that the continued good qualities of Hyperscan and the freedom to pursue the strategy of open-sourcing the product are due to many good people at Intel. I don’t want to make it sound like the story of the product is over. What we learned is captured in the existing Hyperscan product and the processes around it. This post doesn’t focus on the post-acquisition side of things; the privilege of being able to give away your software is while working in a large company is a very different story than the process of getting to that point. It’s also a story that you’re not usually allowed to tell! 🙂
Opinions are my own and not that of any other person, past employer, etc.
So, in no particular order, some opinions about ‘algorithms startups’.
Doing an algorithms startup is a lot of fun
First of all, while there were parts of the process that were awful, if you like computer science, this kind of startup can yield an enjoyable experience. This may vary for different team members and at different times, of course. If you want to work on interesting algorithms and have picked a market where that’s actually rewarded, you might enjoy your work.
Doing an algorithms startup won’t necessarily make you tons of money
Obviously, no startup is guaranteed to make tons of money. But algorithms startups have some extra downsides.
You are attempting to make money from other businesses. You’re going to paid a pittance relative to what they are getting, for good reason. They are building the user interfaces, supporting thousands of customers, building all the boring code you aren’t interested in or couldn’t possibly write yourself.
It’s also very likely that you’ll get paid very slowly. Try not to die in the interim!
The lifesaver for you is that once you get your system accepted by other businesses, they will keep paying for it and you can go and sell the same code to lots of other companies (“Doctrine of Multiple Use”).
You are competing with Free and Open Source if you are closed-source, or you are trying to make money off a product that people can get for free and dissect if not.
I have no experience trying to make money off FOSS software so I can’t speculate about how hard that is.
Competing with FOSS (while still asking for money for closed-source software) is difficult, and you need an enormous advantage. There were a number of FOSS regular expression matchers around when Hyperscan was closed-source, but none of them were close to providing what our customers wanted (large scale pattern matching and ‘streaming’ matching).
I think a startup of this kind can make a fair bit of money, but I would be surprised to hear that it’s in the ‘hyper-growth’ category.
Speculative: What should an algorithms startup do after capturing most of the Total Addressable Market for that algorithm? When are you ready to do that?
This gets into unexplored territory: our answer turned out to be “get acquired”. I would hazard a guess that it’s at least possible for a algorithms startup with a good structure to move into adjacent markets and continue growing. Maybe if you’re good enough at this you could make something big…
Equally speculative would be answers to questions like “when is your core algorithmic product essentially ‘done'”? We continued to tune Hyperscan, always aware of gaps in performance, excessive costs of various kinds (bytecode size, stream size, compile time) and gaps in functionality that might be expected from a regular expression matcher (unsupported constructs).
So we never answered either of these questions – at least not directly – but that answer would be pretty important for a similar startup in a similar place several years in.
Don’t drift into being a consulting business
Stick to the Doctrine of Multiple Use; don’t build special-purpose builds of your software if you can help it, and definitely don’t just wander into consulting if you didn’t intend to have a consulting business.
We had some extra help with this – the Australian government had a nice R&D scheme (now the “Research and Development Tax Incentive”). This mandated a doctrine of “multiple sales” – we couldn’t get a generous credit for work done for just one company. This ‘restraint’ helped us in the long term (not just the money, but the discipline).
We did add a few features in the pre-Hyperscan 4.0-era (before the open source release) that were each ultimately needed by just one customer in the end. These features were always theoretically interesting more broadly and we didn’t do special-purpose builds for single customers; these single-customer features were made available to all. However, they never really got wide adoption.
Ultimately these features were dead-ends – adding a big testing load (adding weird new modes or API functions often increased the test load geometrically) while never getting much use. On the flip side, some of these features were needed to stay alive commercially.
Iterate, and release a Minimum Viable Product (MVP) early, but make the MVP actually Viable
You have to offer something much better than the alternative. A critical functionality improvement or 5-10x on some metric will get you noticed – and unless you’re a drop-in replacement for something else, you’ll probably need that big improvement.
The idea that you build a Minimal Viable Product is now a cliché. It’s harder than it sounds, even when you plan to do it. For an algorithmic startup, there’s a fine line between “unintentionally trivial” and “minimal”.
When we built Hyperscan, the first iteration of what became the successful product (Hyperscan 2.0 – 1.0 was built on different lines and very little aside from the parser was retained) was pretty awful in many respects. Tons of different regular expression constructs would be either slow or not supported (“Pattern too large error”). An extremely early evaluation version even occasionally printed curse words on the console, a behaviour not normally desired in software libraries.
However, we did have some killer features:
Supporting lots of regular expressions at a time (alternatives like libpcre or Java regex only supported 1 at a time),
Streaming (the ability to suspend and resume a regex match, as you would need to if matching a regex across a stream of packets), and
High performance (we were typically quite a bit faster than alternatives – 5-10x was typical).
People were willing to live with a lot of quirks and edge cases if we could deliver on those three items. Over time most of the more obvious quirks and edge cases went away (especially compared to the competition).
We weren’t a drop-in replacement for any other regular expression matcher, so a modest increase in performance was always offset against developer effort at our customers. Evaluations where we couldn’t deliver a big speedup or some substantial new functionality almost always failed. They even failed later, when we were an open source product and were giving Hyperscan away for free.
If your key selling point is performance, but you’re only offering 20% better, you’re in trouble – especially if you’re not a straightforward drop-in replacement for someone else’s product.
Your product will have gaps, but the earlier your customers discover them, the better
Aside from the elevator pitch (hardly the time to tell people how much Hyperscan sucks), we were careful to set expectations early. For us, there was a hierarchy of when the bad news gets found out:
During early discussions (“Your product isn’t a white-box IPS system? Oh.”)
During a technical deep dive (“Your product doesn’t support back-references? No, thank you!”)
During the evaluation when your customer tried to integrate your code (‘doesn’t compile’, ‘API wasn’t actually what we expected’)
When the customer tried to load signatures into our regex engine (“fail at compile time”)
When the customer ran our engine during evaluations (“performance or overheads not good at run-time”)
After the customer has signed a contract and shipped something with our product in it to their customers.
There are a number of terrible strategies that many startups use that pushes the ‘bad news discovery’ downward in this hierarchy. Some of these terrible strategies are technical, some are marketing related.
It’s better to eat the pain early; most developers understand the principle that you’re better off getting a nasty message from the compiler than a crash at run-time. This principle of “bad news early” is good practice beyond that. You won’t screw your customers; you’ll pleasantly surprise them in the evaluations and you’ll get a well-deserved reputation for honesty. You also won’t waste time in meetings or evaluations that can’t end well.
Maybe if you don’t waste their time now, they’ll be more interested in you when your offering is better aligned with what they want.
Testing
Work clean and test everything
It’s tempting to cut corners when you’re a struggling startup. However, you’re actually less set up to get away with cutting corners than a big corporation. If you mess things up, that becomes your reputation – you can’t send a VP out with a few more talking points for his or her weekly golf game with his good buddies who are all VPs at the customer whose product you just stuffed up. If you mess up, you’re dead.
Don’t mess up.
We did this once – we disabled a test (unusually large inputs) after we made a few changes with the intent of turning it back on shortly after (this only affected evaluation versions of our code, not commercially shipping versions of our code). As per Murphy’s Law, naturally this bug was found, not by us, but by an evaluation team at one of the biggest networking companies in the world, on the second day of their first evaluation of our product. The evaluation continued, but with an air of forced smiles and gritted teeth, and didn’t go much further.
Assume anything you don’t test is broken.
You will need to test your code relentlessly, and designing your code for “testablity” is critical. We rejected some features strictly because we didn’t know how to quickly and programmatically find a ‘ground truth’ for how they should behave (needed for our fuzz testing). Other features had their design influenced or dictated by testing requirements.
For example, our ‘streaming’ feature has always been guaranteed to behave identically, in terms of matches generated, to the matches generated by block mode writes. This was very hard – many other regular expression implementations either don’t do streaming at all, or sort of ‘fake’ it (i.e. you can get matches as long as they aren’t spread out too far in the buffer, or too spread out over multiple packets, or on some regular expressions you get them accurately but not all, etc).
By sticking to a strong principle (streaming always works the same as block mode) we could test our stream mode programmatically without having a poorly defined notion of when we were and weren’t expecting to be correct.
The ability to ‘fuzz’ a complex system is a lifesaver, but it comes with a trap
Fuzzing is great. I met a couple Microsoft employees at RSA in 2009 and they asked me: “do you fuzz-test your system”? I admitted “no, we don’t, but I’ll try that when I get back”. We found a lot of stuff – before our real customers did.
We invested a lot of effort into the idea of figuring out how to most effectively test regular expressions – they have a complex structure in themselves, and then you’ve got to figure out what sort of inputs will make interesting things happen inside the bytecodes that we built in Hyperscan. There’s no point testing regular expressions with random data – all those nice optimizations that allow you to skip the hard stuff whenever a required “literal factor” isn’t there will “protect” you from finding your bug. Great for performance, bad for fuzzing. Thus, we put a lot of work into building positive and near-miss negative regular expression test cases. We build systems that were every bit as complex and (arguably) interesting as the regex optimizations itself.
Get interested in innovative ways to test your product. This is not a second-class activity for the “lesser developers” (many other firms have discovered this).
The trap: having a good fuzzer gives you a sense of safety, allowing you to build a more complex system than you might have dared to otherwise. Possibly this is dangerous; I’m still thinking about this point. It’s said that people who think their cars are safer are more likely to drive like maniacs…
Assume every metric that isn’t measured is Bad News for you.
In the same way that everything that isn’t tested is broken, any performance metric you don’t regularly measure (and regularly look at the measurements) is ugly news, showing that your system is bad and getting worse.
Assume everything you don’t measure is probably bad
Long after we supposedly knew what we were doing, we managed to regress our main public benchmark case for open source Hyperscan without noticing. It was differently structured than our normal performance runs, so we didn’t put it in our regular performance matrix – so out of the 21,000 numbers generated per night by our Continuous Performance Monitoring infrastructure, we managed to mess up our ‘brag numbers’. It wasn’t hard to fix, and the performance change resulted from a restructure that likely made sense (most performance numbers improved, and these numbers went back on track long-term), but it was a fresh illustration of a principle that we should have grasped already.
Team Issues
Watch out for Individual Contributor “Tourists”
We all know them. These folks are heading for management by the shortest route possible. They don’t like coding or grunt-work and the minute they can stop, they will be telling people what to do. Computer scientists should be skilled professionals, but many people enter the field with the goal of doing as little as possible of that and to get up into management as soon as they can.
I would be stunned to hear that an architect with 3-4 years professional experience (or a structural engineer, or a doctor, etc.) would deem themselves ready to go lead a team of professionals (often with more experience than they have), but a lot of people coming through computing degrees are expressly on that path.
These people are dangerous in startups because there are few reasonable outlets for their ambition. There’s just not that much of a hierarchy to climb; don’t let them make one to suit themselves.
Conversely, reward your Individual Contributors and don’t dead-end them on compensation.
The converse of this comes from the motivation of many of the “tourists” to get out of these individual contributor jobs: the pay sucks. A mediocre manager is usually paid far better than a really great individual contributor. A well-rewarded ‘technical leadership’ track is a good ideal – rather than dead-ending your technical people or hoping that they’ll magically turn into good person-managers.
Of course, this is a nice trick, given as a startup you probably won’t have any money for a while. But it would be good to think about it, especially before you thoughtlessly splash out a salary $20K per year higher to a random VP of Something-or-Other or a Director of Important Sounding Stuff than you pay your absolute best developer.
A good team is not comprised of 100% ‘A’ players on some “Most Awesome Geek” standard.
It’s actually OK to hire people who are ‘B’ or even ‘C’ players in some areas. The right analogy is closer to one of those team sports with relatively specialized players – being an Australian the natural analogies are cricket or Rugby Union, but our American readers might think NFL. A team full of the ‘best all-rounders you can find’ would be mediocre in most sports; and team full of the ‘best quarterbacks/fast bowlers/etc. you can find’ would be terrible.
Even a small startup needs a diversity of skills. If you put everyone through an algorithms-on-the-whiteboard exam and take the top performers, you might wind up with 5 algorithms / compiler / systems nerds and no-one who knows how to talk to customers, write documentation, test your system or do releases and builds.
In the Computer Science world, there’s an snootiness about certain skills trumping all the others. You need to hire people who are excellent at something you need and willing to learn some new things.
API Design
Build only what you need
It’s a lot easier to hear complaints from customers that your API doesn’t do enough, and fix that, than it will be to wean them off stupid things you put in your API back when you didn’t know what you were doing.
We saw a number of preposterously complex APIs for regular expression matching go by over the years. A minimalist API was popular with customers and easier to test.
We made some decisions that meant our API was not necessarily tiny – having streaming, multiple regular expression support, and having to completely avoid dynamic memory allocation meant that Hyperscan’s API is quite a bit more complex than, say, RE2, but we converged pretty quickly to a small API that we were broadly happy with.
Don’t throw extra features in there if you aren’t sure customers really want them. If you have to do it, mark them experimental and kill them off if you don’t hear much about them.
Listen to your customers but don’t let them design your API for you
We had a lot of really valuable feedback over the years from customers. Getting information about their use case was hugely valuable. However, an exercise that never went well was trying to co-design API features with them. It didn’t seem to work. They don’t know enough about how your system operates to make good suggestions.
Capture significant use cases, even when you don’t have a brilliant solution for the use case.
One thing that worked well was to identify important use cases and capture them in an API even if our implementation wasn’t great. For example, a lot of users wanted to be able to identify matches that occurred in a range of the output – e.g. “This regex /<R>/ matches only if the end of the match is between the 100th and 200th byte”. The user could have been told “hey, we don’t have any particularly good way of handling this – why don’t you do that check yourself, as our solution for this will be pretty much equivalent”. However, over time, implementing optimizations for this case is something we did – which we would not have been able to do if we told our users to go away and bake the solution for the problem into their code, which we wouldn’t see.
So if the API requested creates information you can use, it may make sense to capture the requirement even before you have a good solution.
An example of where we didn’t get this right (initially) was regular expression ordering. Due to the way we initially implemented things, we didn’t return regular expression matches in order by ending offset, nor we guarantee that the user would not get the occasional duplicate match (pretty bad, but it turned out that these things were OK in a MVP). One problem, though, was that users who picked up Hyperscan 2.0 (2.1 added ordering and duplicate suppression) built layers of code that dealt with our inadequacies – these layers of code get baked-in and often sprout other functionality, so even after we guaranteed ordering, those layers of code were there, sucking up performance for a task that was mostly no longer even needed.
This isn’t a license to just build castles in the sky – the requirements that you’re capturing should be important. This principle contradicts minimalism, so be careful.
Miscellaneous Issues
Don’t Bog Down on Trivial Stuff Immediately (or at all)
There are a lot of decisions to be made early in a startup. One pretentious thing you can do is decide that, because your startup is going to grow to take over the world and be really awesome right from the start, you should definitely spend a nice constructive period of weeks arguing over things like coding standards (and maybe some company values and a mission statement). You will find that Parkinson’s Law of Triviality takes over – everyone has an opinion on this kind of stuff and you’ll get a tedious all-in brawl for weeks, resulting in some standards that everyone will go ahead and ignore.
This didn’t apply to programming languages for us (this was more or less dictated by the level of complexity of the compiler, dictating C++, and the harsh environment of the run-time, dictating C, and the huge variety of platforms and tool-chains we needed to support – ruling out pretty much everything else). But I imagine that a nice knock-down-drag-out pissing contest (not a nice combination of mental images, is it?) about programming languages would be another great way to waste the first 2-4 weeks (months?) of your investors money.
Be aware of the risks of ‘bikeshedding’ at all times, not just starting out. However, it seems particularly unpleasant to get stuck in this phase early – the temptation will be strong when the startup isn’t really working yet.
Work Clean – Legals
Another area where it’s imperative to work clean, as a small startup, is legally. I am not qualified to provide legal advice, but it is of enormous benefit to think about this from Day 1. Do you own your code? Can you prove that? Have you dragged in random fragments of code that you don’t know the licenses for? Have you hired corner-cutters whose code will be revealed to be 50% copypasta from Stack Overflow and 40% fragments of unacknowledged GPL code?
I’m not specifically recommending you use a service for automated detection of this (Black Duck seems to do well, but I don’t know whether a small startup would want to spend their money on this); just don’t hire people who do that sort of thing, and remind junior developers that it’s not OK.
Similarly, a lot of startups join consortia and relentlessly announce partnerships that amount to little more than a press release and a exchange of banners on your website. These agreements may not bring you much more, but bear in mind, every bit of paper you accumulate will be something that you’ll be hearing about again during due diligence.
Every bit of paper you sign is a potential millstone. Don’t do a whole pile of important-sounding ‘businessing’ stuff that doesn’t get you anything and involves you signing tons of legals.
Think really carefully before you splash out small shareholdings to random people. You’ll need to go back to these people during an acquisition.
Dance like no-one’s watching; enter into agreements like every single thing you have ever done will be meticulously examined by one or more teams of lawyers working on behalf of a Fortune 500 company, as well as your own team of lawyers, who will be billing you for the time.
Work clean – Static and dynamic analysis
In our experience, running every static and dynamic analysis tool you can lay your hands on is worth trying. Both customers and acquirers down the track will thank you. Some tools are garbage, but as a rule, being clean on things like valgrind and clang static analysis and running with all warnings switched on and set to stop compilation was worth the trouble.
This is a day-to-day hit; you will occasionally have to do Weird Things to satisfy these tools. That’s a steady dull pain, but it’s better than the sharp pain you’ll experience if one of these tools could have caught something and didn’t.
Build in an niche appropriate to your scale; don’t take your tricycle out on the expressway
One of the keys to our success is that hardly anyone attempted to muscle in on our territory. While it seems that good quarter of the world’s serious computer scientists have a pet regular expression project, very few of these projects are ever built out as a commercial product. There were a number of regular expression libraries that had quite decent performance on some of our key use cases, but none of these libraries had the work done to make them robust and high-performing across the use cases we handled.
What competition did exist, fortunately, thought hardware-accelerated regular expressions were a great idea. Perhaps this is a stroke of luck that happens only once in a career.
Our job was doable with a small team over a number of years because ‘high-speed software regular expressions’ was a niche: profitable enough, but not too crowded. I’m glad we hadn’t decided that “video compression” or “neural networks” or “machine translation” was actually our niche.
Expect to fail evaluations and keep trying
We had evaluations at big name companies that failed 4 or 5 times before finally getting a win. Sometimes the teams wander away, sometimes your product is just not good enough, sometimes they were just kicking the tires with no intent of ever doing business.
If you go single-threaded with the intent of landing that amazing nameplate customer, it might well kill your company. They might say ‘no’. Worse still, they might say ‘yes’, but you have invested so much time in them, and waited so long for revenue, that you’ll wish you failed the evaluation.
Persist and chase many opportunities; also try to find out what went wrong (in case there’s a next time, or in case the mistakes you made will effect you elsewhere). The latter is surprisingly difficult; in fact, it’s often hard to elicit feedback of any kind – even from a successful evaluation. After bad – or even good – results, you may be like these two gentlemen from the Coen Brothers’ “Burn After Reading” (caution: strong language)
Build a huge database of benchmarks and actually look at them
One of the big advantages that we built over the years at Sensory Networks was a huge database of regular expression patterns that customers had shared with us. We treated this with great care and didn’t leak information from it – but we used it relentlessly to try to improve performance, even on cases where customers had wandered away.
Subsequent dealings with other companies often left us amazed at how little data our competitors had on the complex workload we were all supposedly trying to make go faster/better.
This took a fair bit of pleading with customers to get this information. One of the main selling points was that “if you share your use case with us in enough detail – or something that looks enough like it – we will measure performance on your case and if we mess up our code base relative to your usage we will discover it in 12 hours, not 4 months after we make the mistake and 2 weeks after we send you the release”.
This worked well, but not perfectly. Some of our best customers never, ever showed us their workloads.
As mentioned above, while it’s nice to have all these benchmarks, it helps to look at the results of running them, too. If there are 24,000 metrics on your dashboard you’re probably not looking at them any more.
Expect to be evaluated by the person whose code will be replaced by yours if the evaluation succeeds
If you are an algorithms library, the person who evaluates you will probably be the person who previously wrote the library to do whatever your product does – good luck! They are the domain expert, and if you’re unlucky, they Hate You Already.
There are a surprising number of honest and self-critical computer scientists out there working at big companies who will give respect where it’s due, even when this means admitting that someone else wrote better code (and sometimes, people were glad to give up the role and move on). Sadly, this isn’t universal. Expect to have the goal-posts moved frequently: you will often be competing with someone else’s system that’s being ‘generously benchmarked’ while your system is being ‘adversarially benchmarked’. This means that you really can’t afford to have glaring weaknesses in secondary metrics.
Our primary metric was essentially raw performance. However, there were a host of secondary metrics (size of pattern matching byte code, size of stream state, pattern compile time, etc.) and it was impossible to tell in advance who cared about what. Even worse, in an adversarial benchmark situation, you can expect whoever is doing the evaluation to suddenly ‘care’ about whichever metric makes your code look the worst.
Bonus anti-pattern to look out for: finding out that for months you have been talking to one evaluator who has 100% control of process and is hiding their results away from the rest of their company; you will go back through the email chain and notice that no other email address has ever appeared. Who is their boss? Who is their coworker? If this happens to you, stay not on the order of your going but Go At Once!
Evaluations seem to go a lot better if they are bottom-up and engineer-driven rather than top-down and manager-driven
We had a number of very successful evaluations at companies where the engineers were on our side and they persuaded their management that spending money on us was a good idea. Later on we had a number of evaluations where management of a company descended on their engineers and told them “use Hyperscan”. These evaluations were typically disasters, even though we had a better product and on paper the opportunities were promising. When it comes down to it, engineers don’t like being told what to do.
Expect to not be able to announce successes
For the entire history of Sensory Networks, we were almost never allowed to announce “design wins”. Most vendors who used Hyperscan were adamant that this not be mentioned publicly. I expect this would be similar for most algorithmic startups – too many announcements of this kind is presumably a free invitation to the competitors of those vendors to duplicate their functionality (we use signatures from X, a pattern match engine from Y, hardware from Z, and …).
So, expect your ‘News’ section on your website to be a bit more threadbare than you hoped.
Contract negotiations: don’t lose your nerve
Expect people to try stuff on. Many – most, in fact – of our customers dealt fairly with us as a small company. A few people, at a few companies, tried outrageous last-minute surprises in contracts. Keep your nerve; if that company make-or-break deal gets a horrifying provision added at the last minute, tell them to go away and do better.
Trying to impose exclusivity or various other limits on our freedom of action to sell Hyperscan as we pleased was a popular pastime, but no-one really insisted.
Some things that didn’t seem to be missed
A nice looking website.
Help from people who have nebulous jobs “helping out startups” (I don’t mean lawyers or accountants, I mean the Picks and Shovels crew that seem to know the real way to make money in a gold rush).
Having a roadmap that stretched more than about 2-3 releases and 6-9 months into the future; we almost never achieved any of the ‘long term’ items on our roadmap.
Finishing off emulating all the weird bits of libpcre, which was our ‘reference’ library for regular expression semantics (and generally an excellent base for semantics), or supporting a host of other syntaxes and semantics
Joining important-sounding consortia that just amount to having a banner on someone else’s website in exchange for having your banner on their website. Does anyone care? The same goes double for being awarded ridiculous startup or small business prizes (“East Sydney’s Most Agile Startup 3 Quarters Running!”), exchanging physical plaques (!), sponsoring random things. etc.
Getting all sorts of mysterious certifications about how great our development methodology was, which often seemed to amount to telling some organization “our development methodology is pretty great”, writing a cheque, and getting the certification, without anyone ever actually looking at our code. Odd.
Conclusions, Sort Of
So, that was a bit of a stream-of-consciousness series of opinionated “hints and tips”. I don’t think there’s a really solid conclusion here – we got some things right-ish and some things wrong-ish and didn’t do too badly.
I’d be lying if I said that I thought that doing this type of startup was a route to enormous startup wealth. I’d be surprised to hear that a company can become a 1000X type Silicon Valley success story from algorithms alone; I’m pretty sure that you have to capture a lot more of the value than can be captured if you ship a nifty library and go home. I do think that this kind of startup can yield a reasonable outcome and someone sufficiently interested in their work can have a pretty nice time and learn a lot, while getting paid reasonably for it.
I’d be interested to hear comments or criticisms or links to other similar startup stories. I’d be particularly interested to hear stories of what it’s like on the open source side of the fence; the path taken by Sensory Networks now seems somewhat of a closed-source anachronism.
During that post, I provided throughput numbers for these sequences but didn’t show latency. This is a critical distinction, and it doesn’t pay to be confused about the the two. I would rather avoid the rather cringeworthy formulation from the Mythical Man Month (where women are “assigned” to the task of bearing children!) and stick to the metaphor of boiling eggs: a suitably large pot of boiling water could boil eggs at a throughput of an egg every 10 seconds, but cannot provide you with a 3-minute-boiled egg in less than 3 minutes.
It is important not to confuse the ability to do something in, say, 10 cycles vs the ability to do 1,000 somethings in 10,000 cycles. The former is always at least as hard and usually much harder. This distinction holds all the way down to the single operation level: for example, a modern x86 processor can launch a multiply operation every cycle, but requires 3 cycles to know the result of a given multiply.
Modern computer architecture conspires against us when we wish to measure latency. Attempting to measure the latency of a single short code sequence is quite error-prone due to the overhead of the various performance counter or clock measurement calls.
Throughput is easy to measure on a larger scale, as we can measure thousands of iterations and establish an average cost per iteration. However, well-written code will usually attempt to minimize dependencies from one iteration to the next. When we attempt to measure, say, the branch-free code of SMH, there is little to prevent a modern, out-of-order processor from getting on with the next iteration or two while the previous iteration is handled.
I tried two approaches both attempting to measure the latency of the various SMH sequences. The first was to insert an LFENCE instruction between each SMH sequence but otherwise keep the code the same. Note that LFENCE in this case can be switched on and off by a macro.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The second approach was to make the location that was read by an SMH sequence depend on the result of the previous SMH sequence. Since I didn’t want to introduce a spurious ‘jumping around memory’ component to the benchmark (which would always be absent from the equivalent throughput metric), I made sure that the previous SMH sequence always happened to return zero (no match): we know this, but the architecture and the compiler don’t.
Creating long chains of dependent operations is also how Agner Fog (and others) measure latency; those who have not yet seen Agner’s Software optimization resources are in for a treat.
The code to measure SMH latency is below (note that LFENCE is switched off by the preprocessor as needed and was not used in the latency-test version of this code at all):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Observe the “tmp” variable in the gist above; it is always zero, but we cannot safely start our matching operation until the architecture has the result of the previous match operation in hand (Intel Architecture has many fascinating optimizations, but generalized value prediction is not one of them).
This gives us somewhat of a hybrid creature: “steady-state” latency. The compiler and architecture are still free to load things into registers that don’t depend on the actual computation – so this latency number is perhaps unrepresentative of a ‘cold start’. However, it is a reasonable measurement of the latency of a single operation in a well-optimized code base.
SMH Variant
normal
no unroll
LFENCE
SMH32-loose
Throughput (ns)
0.89
0.98
10.62
Latency (ns)
7.03
6.92
10.65
SMH32
Throughput (ns)
1.12
1.15
11.02
Latency (ns)
7.25
7.30
10.89
SMH64-loose
Throughput (ns)
1.35
1.44
11.03
Latency (ns)
7.63
7.61
11.36
SMH64
Throughput (ns)
1.62
1.66
11.67
Latency (ns)
7.95
8.00
11.61
SMH128-loose
Throughput (ns)
2.80
2.67
12.39
Latency (ns)
8.97
8.14
12.91
SMH128
Throughput (ns)
3.32
3.08
12.82
Latency (ns)
9.78
8.55
12.91
The above numbers seem reasonable based on a walkthough of the code. I also measured the effect of turning off my manual 8-way unroll. I had focused on smaller models and the metric of throughput as I tuned SMH; it’s marginally interesting to note that latency is generally better without an unroll in the measurement loop if not decisive.
The LFENCE results are hard to interpret – they seem to generally track the latency of the normal case plus around 3.5ns. More work is needed to confirm this; it would be nice to have a way of getting a latency number out of the system that doesn’t rely on an ability to introduce contrived data dependencies from one iteration to the next.
I feel reasonably confident that SMH can be said to do its work in 7-9 cycles; note that the overlap of iterations required to hit the full throughput (looking at the above table) must have to be as many as 8 iterations for the cheapest cases. As always, this implies that being stuck in the ‘latency world’ is miserable – try to phrase your computations to stay in the ‘throughput world’ whenever you can.
Today I’m going to share with you one of my favorite instruction sequences.
PSHUFB
PAND
PSUBB
PCMPGTB
PMOVMSKB
ANDN
ADD
AND
AND
LOAD
OK, got it? That’s the post. Have a nice day.
Perhaps a little more explanation is in order, especially if you weren’t next to my cubicle for what were no doubt 11 very long years during the creation of Hyperscan. The above sequence, which I have dubbed SMH (an acronym which stands for “I am Not Going to Explain”), appears in various forms in Hyperscan, and has a few expansions and variants which I’ll discuss. I think a full expansion of all the fun of SMH, and a codebase to match, will have to wait.
This sequence looks fairly banal – but it can accomplish a huge range of matching tasks, not all of which are traditional pattern matching tasks. Let’s walk through a basic application and we’ll get to more elaborate ones in later posts.
Keep in mind that the basic unit here is asking questions composed of a bunch of byte-level predicates comparing our input to queries we prepared earlier.
Everyone likes a good Prefix Matcher – Prefix or Suffix matchers crop up all over the place in pattern matching as a basic building block. There are plenty of traditional implementations of this (generally involving DFAs or hashing/Bloom Filters).
I’m going to focus on a case that allows SMH to be displayed without too much extra complexity: small-set Prefix matching of literal strings no greater than 16 characters.
Suppose we want to match a few animal names and map those to some sort of id: we have {“cat”, “dog”, “mouse”, “moose”, …}. Here’s a straightforward approach to doing this, assuming we have no more than 32 characters overall in total and a machine handy with AVX2 (if you don’t, buy yourself a better computer and give Grandpa back his Ivy Bridge, or translate everything I’m saying into Neon – there’s nothing here that’s all that Intel specific, but I don’t have a fast ARM workstation so y’all can suck it up and read AVX code):
Load 16 bytes of our input from memory and broadcast it to high and low lanes of an AVX2 register
Shuffle the input with a pre-prepared shuffle mask, so that we can consecutively compare the first 3 bytes against cat at bytes 0..2 of our register, the first 3 bytes again against ‘dog’ in bytes 3..5 of our register, etc.
Compare the input against another pre-prepared mask, this one containing our strings: so the register would pack in ‘catdogmousemoose’.
Use VPMOVMSKB to turn the compare results (which will be 0x00 or 0xff) into single bits in a general purpose register (now, you can put your SIMD units away).
These steps are illustrated below:
Take the Most Significant Bit of each string in the mask – if we are packing our strings from left to right (it doesn’t really matter which way we do the comparisons) we would have the comparison of ‘cat’ so that ‘c’ is in bit 0, ‘a’ is in bit 1, ‘t’ is in bit 2, and we would declare the bit 2 part of our Most Significant or “high” end, so bit 2, 5, etc. would be our high mask. We’re going to make a temporary mask which is the result of our VPMOVMSKB with the ‘high’ mask zeroed out.
I refer to this as ‘digging a hole’. We’ll need that ‘hole’ later.
Now take the corresponding ‘low’ mask (the LSB end of each string) and simply add it to our temporary.
The effect of this will be that if, and only if, all our other bits in the mask are on, there will be an arithmetic carry into that ‘hole’ I mentioned (and you can see why we needed it – we certainly don’t want to carry beyond that point).
Now AND the original mask (not the high mask, but the original mask we got from PMOVMSKB back in). Now the high bits are on if and only if every comparison bit associated with the string is on.
We then AND by our high mask again to turn off everything but our high bits.
We can use LZCNT (leading zero count) to find our first high bit that’s set. We pack our strings in order of priority, so the ‘winning bit’ (in case two bits are on – possible if our strings or later patterns overlap). We don’t have to do it this way – we might want to report all matches. For now, we’ll report a highest priority match.
This LZCNT is then used to read from a table that has ID entries only for the bits that have high bits set (the other entries in the table are never read – this wastes some space but means we don’t need to compress down our table).
Steps 5-10 are illustrated here:
So – that’s the basic algorithm.
This gist shows the edited highlights (no debugging guff – I have some code that prints out the process in greater detail if that’s what you’re into) of steps 1-9: there’s really not that much run-time code.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
There are obvious extensions to handle more than 32 ‘predicates’. We can build a 64-wide version of the above by simply gluing two copies of steps 1-4 together with a shift-by-32 and an OR at the end. A 128-wide version is four copies of steps 1-4 and two separate copies of steps 5-9 with a little bit of logic (a conditional move and an add) to put together our two LZCNT results to turn the result of doing 2 64-bit LZCNTs into a single 128-bit LZCNT.
The above sequence is fast, and reliably so: it doesn’t have any branches and it doesn’t make complex use of memory, so its performance is pretty much constant regardless of input.
It can be made faster if we take a few shortcuts – suppose we have plenty of room in our model, whether it be 32, 64 or 128 bits. We might have, say, 4 strings with 5 characters each, so we’re consuming only 20 slots in a 32-bit model. In this case, why ‘dig holes’? Instead, we can reserve a slot (“gutters” instead of “holes”?) at the high end of the string with a guaranteed zero compare – this means that all we need to do is add our low mask and filter out the carries from the high end, so the ANDN/ADD/AND/AND sequence loses 2 instructions. We refer to this as the “loose fit” model as opposed to the “tight fit” model.
Here are the performance numbers in nanoseconds on a 4.0 Ghz SKL workstation:
Fit
Predicate Count
ns per sequence (throughput)
Loose
32
0.888
Loose
64
1.38
Loose
128
2.82
Tight
32
1.14
Tight
64
1.65
Tight
128
3.37
I describe these as throughput numbers, because you won’t get a single SMH lookup done at anything like these speeds – the latency of these sequences is much higher than the throughput you can get if you have lots of these sequences to do.
A future blog post will look into generalized ways to measure this latency specifically (I had a unconvincing experiment with LFENCE). In the meantime, be sure to think carefully about experiments where you “do something in N cycles” where you actually mean “doing 10,000 somethings is N*10,000 cycles” I recommend the following three step program. 1) Cook 18 eggs in a pot for 3 minutes. 2) Convince yourself that throughput == latency. 3) Throw away your original eggs, cook another egg for 10 seconds and bon appétit!
Here’s a debug output showing a couple iterations of one of our models (SMH32-loose, the simplest model). I use underscore instead of zero as it’s easier to read:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The curious can go to Github and poke the system with a stick. I cannot guarantee that it won’t fall over; this project is very preliminary.
SMH: Full Sequence
(I will not illustrate this with a movie reference)
At this point, you might be excused for wondering why I called SMH the “Swiss Army Chainsaw”. The instantiation above is pretty simplistic and seems to be covering literals only. The codebase as it stands really only allows this; there’s no compiler to do anything but literal prefixes.
However…
1. Shuffle allows discontinuous things to be compared
Because we are using shuffle, we don’t have to select contiguous parts of a string. Better yet, we don’t have to pay for bits of the string we don’t select to compare on. Using regex notation, the very same sequence could just as easily match /a…b/s as /ab/ and both take the same number of predicate slots.
This means we can range over data structures (subject to our limit of 16 bytes; more on that later); we don’t just have to compare strings in buffers.
2. The full sequence allows masking, ranged comparison and negation
The full sequence adds a couple extra SIMD instructions to the front-end, and changes the nature of the comparison from ‘equal’ to ‘greater-than’.
Inserting an AND into our sequence allows us to carry out a ‘masked’ comparison. This allows us to do some fairly simple things – e.g. make caseless comparisons of alphabetic ASCII characters, check individual bits, or look for a range of values like 0x0-0x3 (but not an arbitrary range).
But even more fun – leave the AND into the sequence and subsequently carry out a subtract and change the comparison to ‘greater-than’ comparison (PAND, PSUBB, PCMPGTB).
This gives us all the old power we had before (if we want to target a given value for ‘equal-to’, we simply use PSUBB to ensure that it’s now at the maximum possible value (+127, as the AVX2 comparison is on signed byte) and compare-greater-than with the value +126. However, we can now also detect ranges, and we can even negate single characters and ranges – it’s just a matter of picking out the right subtract (really, PADDB works just as well) and compare values.
I admit I have not really thought through whether there is interesting power granted by the combination of PAND and the PSUBB/PCMPGTB together; I have really only thought about these in a one-at-a-time fashion. It might be better to follow the PSUBB with the PAND. Insights welcome.
3. The bit arithmetic at the end of the sequence can model more than just ADD
The sequence – whether ‘loose model’ (ANDN, ADD, AND, AND) or the ‘tight model’ (ADD, AND) – carried out over the general purpose registers is used to calculate a series of ANDs of variable length bitfields and produce exactly one result per bitfield.
It has more possibilities:
With a bit of work, it’s possible to handle overlap within the predicates. Suppose we have two strings “dogcow” and “dog”. We can overlap these as long as we either are (a) using the loose model (so we have a safe spot after ‘dogcow’ already) or (b) we separate our ‘dig our holes’ masks and our ‘extract the final comparison masks’. After all, if we overlap “dogcow” and “dog” we don’t want to ‘dig a hole’ at ‘g’, or else we don’t get a carry all the way to the ‘w’. So in a tight model we will still ‘dig a hole’ at “w” but we will have to treat seeing a ‘1’ after than process is done differently – in fact, we will find a match for all of the bolded characters in “dogcow“.
Note we also need to make sure that the index for successfully seeing “dog” is copied not just to the slot corresponding to “g”, but also “c” and “o”, as if we see “dogco” that’s a match for “dog” but not “dogcow”.
Bizarrely, we can handle OR over some predicates, in some order, and even nest at least one AND-term within that OR (but not two).
So, suppose we wanted to match (in regex notation) /ab[cx]/ – “a, followed by b, followed by c or x”. We could use 4 slots, comparing the first 2 characters in the typical way, then using 2 byte-predicates against the third. We would then, instead of adding the equivalent of binary 0b0001 (the way we would for, say /abcx/), we add binary 0b0011 – so either the ‘c’ matching or the ‘x’ matching will cause a carry out of our last 2 places. The only difference that results is what’s left behind in bits we don’t care about anyway.
Even more odd: suppose we wanted to match /ab(cd|x)/. We can still do this – by ordering our predicates to match a, b, x, c and d in appropriate places. We then add 0b00101 to the mask, which gets the carry we need iff we have “cd” or “x”.
It is not possible to do this trick for an arbitrary combination and something as simple as /ab(cd|xy)/ cannot be done. Only a boolean function where some ordering of the variables allows us to arrange all possible ‘true’ values above or below all possible ‘false’ values can be handled in this way.
In anyone has any theoretical insight into how to express which functions can and can’t be modeled, please let me know!
Future thingies
Needless to say, this can all be made far more powerful (in case it wasn’t powerful enough) with better instructions. While my long-standing love affair with PSHUFB has already been demonstrated and will be demonstrated again, the limitation of 16-character range is irritating. VBMI and VBMI2 in particular introduce more powerful capabilities, and ARM Neon machines already have the means to do generalized byte shuffles over 1-4 registers. There are also possibilities for using larger data items for both shuffles and for the compares (this yields a different set of functionality).
If anyone wants to send me a Cannonlake machine, or a ARM Neon workstation, I’ll give it a shot, without fear or favor.
A pre-shuffle using the existing AVX2 or AVX512 permutes could extend the range of the finer-grain PSHUFB shuffles, although the functionality provided is a bit complex and hard to characterize.
All this will be explored in due course, but not until the basic SMH models have been fleshed out and grown a slightly usable API.
Summary: The Case for the Swiss Army Chainsaw
Armed with the above features, it seems possible to handle an extraordinary number of possibilities. Note that range checks on larger data types than simple bytes, can be (somewhat laboriously) composed with these features, and obviously the whole range of mask checks (as per many network operations) are easily available.
These comparisons could also be used to combine quantitative checks (e.g. is TTL field > some value) with checks of strings or portions of strings in fixed locations.
The fact that we have a logical combination of predicates could allow checking of a type field to be combined with checks that are specific only to the structure associated with that type field – so a data structure which leads with a type field and has several different interpretations for what follows could be checked for properties branchlessly.
Needless to say, actually doing this is hard. The run-time is easy (add 2-3 more instructions!); the compiler and a good API to express all this – not so easy. I’ve illustrated a simple application in this post, and can see more, but have to admit I don’t really quite understand the full possibilities and limitations of this sequence.
Postscript: A Notes on Comparisons To Trent Nelson’s Prefix Matcher
This work has some similarities to the recent Is Prefix Of String In Table work by Trent Nelson. I’d point out a few issues:
This work is measured in a tighter measurement loop than Trent allows himself, so these numbers are probably artificially better. I’m allowing myself to inline the matching sequence into my measurement code as the SMH sequence here is in a header-only library. I don’t think Trent is doing the same thing so he may be paying some function prologue/epilogue costs. If I get rid of my unrolls and inlines I lose a couple cycles.
The SMH work presented here isn’t really intended for a larger-scale standalone: it would be more typical to embed it as a second-stage after a first-stage lookup.
Despite this, out of curiosity, I tried putting Trent’s testing strings into my matcher – one of the strings is too long (I can’t handle >16 length strings) but after that is trimmed to length 16, the matcher can fit those strings in the 128-predicate ‘loose’ model or about 11.3 cycles throughput.
If one were to select on (say) the first 11 bits or so of the buffer and look up a SMH data structure after 1 layer of indirection (SMH is too big to really make it fun to have 2048*sizeof(SMH) bytes, so indirection is needed) – a simple load, AND, load sequence, it seems obvious that the “loose 32” model could cover the case (3.6 cycles throughput plus added costs from the loads and AND, as well as whatever costs happen from having to go back and forth between multiple SMH sequences rather than using a statically determined set of sequences continuously). As a bonus, this arrangement could strip the first character out of the workload, allowing us to cover 17 characters.
The SMH code is branch-free and won’t be affected by branch prediction. Trent’s performance analysis doesn’t really cover the effects of branch prediction as it involves benchmarking with the same string over and over again – it is, of course, very hard to come up with realistic benchmarks as there’s no real ‘natural population’ of input to draw from.
I don’t yet bother to deal with length of the strings, which is naughty. Trent is more responsible. However, the more full SMH model is capable of including length information in its predicate calculations, and an alternative strategy of ‘poisoning’ our input (loading ‘out of range’ characters with values that cannot occur at that position in any valid string – not hard when you only have 16 different strings and no wildcards) is also available.



 (the pictured dish is apparently materials for
(the pictured dish is apparently materials for